
There isn’t really a recipe for building a AI first product. Reason – There aren’t many ‘product’ people who understand enough Machine Learning. It’s a rare intersection.
This blog post proposed a way how product people can build features that are powered by AI. Just like any new technology it looks like magic. But at the core is some simple maths, deep consumer insight and some machine learning.
- Words:5802 (Skim friendly)
- Type: Post
- Video:0
- Slides: 0
- Topic: Humans Of EdTech
- TIME: 6 Minute
Great. So today we’re going to look at a step-by-step guide to building AI-first products. There isn’t really a recipe for building AI-first product. The reason there aren’t many people who understand enough machine learning & product, it’s a rare intersection. This blog post proposes a way – how people can build features that are powered by AI. Just like any new technology, it looks like magic, but at the core is some simple maths, deep human insight, and some machine learning.
What is the step-by-step guide to building the AI-first products?
Now, let me go back to my first-hand experiences. Three of them. And I will speak about both of them at length. One is about building a product – 9Content, for which I built out a prototype. But we did NOT productize it. Second, is specifically in the skill competency framework at GreyAtom. Early stage Chatbot at Customer360.
So the number one thing is that whenever you’re building a feature or product – it’s not like, now we’re going to put AI in this. That is possibly one of the suboptimal ways of thinking through building AI based products. Typically, you have a problem, and you find a solution to the problem which is based in automation. And by bringing in a certain automation, you can save something for the business. That is grow revenue or cut cost. More often than not, it is the automation is the trigger. So whether it is replacing humans; tele-calling agents with chat agents, chat agents with chatbots.Three
Because when an agent is calling and talking to someone, only 1 agent can talk to 1 customer. For chat, 1 agent can chat with 10 customers. So the same person can cater to more requests. Now similarly, chatbot can take the ratio much higher. And as and when the chatbot essentially fails, the chatbot no longer can resolve the queries, it escalates to the human agent. So, that essentially is how the feature set typically ends up building. When we looked at the example of a chat bot, replacing the chat agent or chat bot, replacing some amount of interaction that happens on the website.
It doesn’t start with “Okay, I want to introduce AI” it starts with I want to start my business problem.
I want to take the count of tele calling agents from 1500 to 900, over the next 12 months, and that is typically the thought process. And Artificial Intelligence (AI) or Machine Learning (ML) may not always be the solution for all the problems that we have.
Another use case.
Content marketing is tricky. You publish a blog post and you want to see what kind of impact that this blog post has generated. Typically, a click through rate impressions-to-clicks ratio, and having an attribution regarding ‘whether this person ended up converting or buying a product or free trial?’

Photo: Mayuresh Shilotri and Mitul Thakkar on the streets of San Francisco validating ‘9Content’
Some of these things are better quantified with multi touch attribution methods. What we have attempted in 2016, specifically with the content recommendation system essentially was – “Can we quantify the impact of the content?”.
Second, ‘Can we have a recommender in place, which will tell you what content to build, how to build, where to build, when to publish? Making the value chain increasingly predictive. So, over there, the entire thought process was that we want to quantify phenomena. Which at this point in time observed in the actual world.
The thought process was that we need to build a mathematical model, once we reached a point, and once we built out the first rudimentary mathematical model, that’s when we discovered that this mathematical model now needs to be calibrated, tuned, regressed, and it needs to improve, it needs to evolve. And the inputs are essentially fluctuating. And there are multiple data points over there. That’s when we felt that we can model some of these things using certain machine learning techniques. So the prediction or the classification that we wanted to do over there typically came down to the mathematical model that was based on it. And the mathematical model is based on phenomenon that was happening in the actual world. We need to better control to have a better traction, need to have a better understanding of it.
It was never that I want to build a machine learning model, because always I need better control, I need more bang for my buck, I need to save my money. Hence, solving the problem.

Finally, looking at the third example, where at GreyAtom, we wanted to establish the skill competency framework. The need here was in B2B business. How can you establish ROI on for companies spend on people upskilling? What is the return on investment on the investments that companies are doing on the training? How can you can quantify that?
Can you model a person as a bunch of competencies, a bunch of skills? And can we can make this domain agnostic, not just limited to data sciences. That was the problem statement. As a person with skills and competencies, which vary with time, which grow with time, and which also decay with time? How can we mathematically model it now, so we broke down from person, to the assignments to the projects, to the behaviour to the various indicators? And then we put on a very basic, simple model that this is how you need to build it out. And this is how you can measure the skill competency metrics of a person.
Structuring the Competencies
- Qualification Packs by NASSCOM (Currently NOT defined for Data Science Roles)
- http://www.sscnasscom.com/ssc-projects/job-roles-and-qualification-packs/
- Hierarchy as per DS-BoK (Need to customize this to more realistic proportion)
- KAG (Knowledge Area Group)
- KA (Knowledge Area)
- KU (Knowledge Unit)
- http://edison-project.eu/sites/edison-project.eu/files/filefield_paths/edison_ds-bok-release2-v04.pdf
- See Table on Page 18
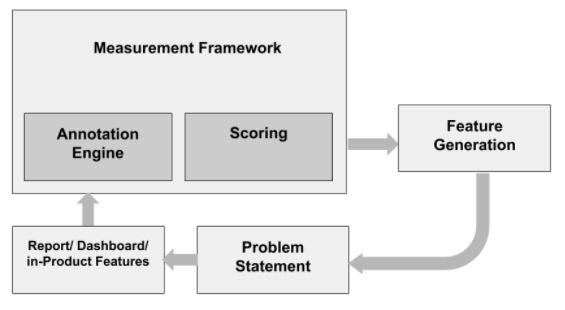
Phase #01
- Annotation Engine:
- Propose a Semi-Automated/ Automated annotation scheme for codebase
- Scoring Engine:
- To propose a scoring scheme that will capture the current state of the learner
- Skill vs. Competency Matrix
- Propose a Measurement Framework to measure the skills/ competencies of the learner
Phase #02
- To enable a reporting framework to allow for various reports and dashboards
- To expose features to open possibilities for data science driven studies
So again, the need was not let’s build out a machine learning model. It was, ROI calculation for upskilling.
Let’s put together a simple mathematical model where you’re able to just represent the person as an aggregate. So once we established the data ecosystem, once we put out the landscape over there, that’s when we realised that yes, there are multiple opportunities, where now some of these metrics can also be used to predict certain other indicators. So there is causality that can be established. There are certain behaviours and traits that are coming out because of the establishing of the underlying metrics.
What we typically loosely call as learner analytics, the foundation of that is to have a very rich annotated data, behavioural data, which can be a very strong surrogate for the underlying behaviour, or trait or skill, or a competency or a part of the personality. So that’s how the thought process begins.

So what I just wanted to bring out in all these three examples,
Customer360, I want to drive down costs – i.e.: bring down the number of chat agents. That is an enabler of business growth with respect to cost savings
9Content – How do you put together a mathematical model and that is the engine of growth regarding a content recommendation? What I should build? What I should not be building?
GreyAtom – the skill competency framework.
It is not that you want to use machine learning for the sake of using machine learning. You want to solve a specific problem. And once you start solving them, then you realise that, once you enable the data infrastructure, some of these underlying relations and laws, they either discover themselves; manifests themselves in supervised and or unsupervised ways. It has a consistent predictive value. And there is advisory and timely intervention that can be planned with it.
Difference between Econometric School of Thought and Machine Learning
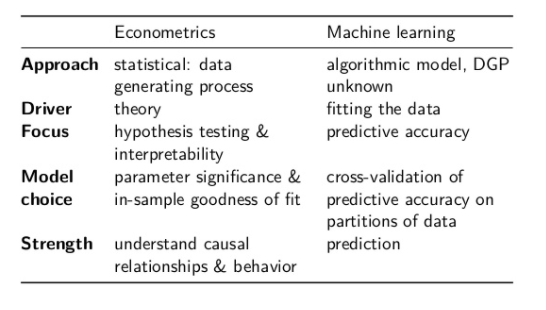
We are going to look at the econometrics school of thought, and the machine learning school of thought. Now if we do a quick literature review, we will come to know that econometrics school of thought is there. The phenomenon that is being modelled statistically has some sort of sort of foundation in reality, and some sort of a law is very well defined. Econometrics School of Thought is confined to economics. People also put it differently that this is econometrics can be parametric or nonparametric.
Machine learning is not interested in causality, whereas econometrics has some basis in causal relations. Econometrics uses the whole data set, but machine learning splits the data sets in training & fit. So there is ton of hairsplitting that we can do. So, my aim here is not to give you the differences, but my aim here is to tell you that yes, there is an approach where you can look at the phenomena around you, which can be marketing phenomena, sales phenomena, biological phenomena, learning phenomena, customer phenomena. You will be able to model them mathematically using some sort of rules, laws, observations, and something that has foundation in practice.
In machine learning school of thought, you can essentially have a phenomenon or variable that defined and governed by a few other variables, a few other features, but there need not be any causality or that may be purely coincidental. It may not have a basis in theory. Hence, we are looking at these two schools of thought.

Further Reading:
Mathematically modelling the RoI on Content Marketing
Mathematically modelling is an iterative process. We start with the basics and gradually embellish the model to factor more of the reality.
This blog post proposed a way how product people can build features that are powered by AI. Just like any new technology it looks like magic. But at the core is some
Step #01 - Start with an Econometric School of thought
Now, the reason I’m bringing it out is when you’re starting out, regarding trying to build something which is AI enabled, or machine learning driven, you may want to safely start with modelling things, looking at things from the econometrics school of thought, because that forces you to put the causality lens, let me simplify this. If you’re saying that people are getting jobs in your cohort, that is because people have studied well. So this is a simple English statement, because someone has studied well, they have got better jobs. And you’re also saying that their communication skills are very good. So it is a very simple thing. People who study well and who have good communication skills, get jobs. Now this is a very simple equation. Whether the person will get job or no can be modelled by too variables. Communication skills and Effort. This has foundation in logic. This has foundation in reality, this may also be universally observable or can easily be explained. I suggest, we start with the econometrics school of thought.
Over a period if you can uncover features and phenomena which describe the behaviour of getting a job basis of some completely different variables and more accurately – we should go with it. But to start with always start with the econometrics school of thought because that will help you build things stepwise, you’ll never build something huge big on day zero. You always build it step wise. So, that’s the number one thing you know start with an econometrics school of thought. Then see what data pans out; what kind of prediction accuracy you’re getting; what kind of value are you adding to the business and then and then and only then start complicating things by choice.
Few Books that can help. Read Reviews


Step #02 - Don't say AI Inside. It should feel like magic.



Second, the user must not know that AI is at play. That is an important thing. So, we come across a lot of these websites, where essentially you are matched with some other person and then mutual common meeting is arranged. Sites like SupremeMinds, CoffeeMug & LunchClub. They will communicate this as this is an AI driven matching engine, this is an AI driven matching engine. So, it is very easy to typically deconstruct what is happening underlying over here.
They will ask data from you and then ask for some data from the other person. And they are going to calculate some kind of distance between the two people. Who have the least kind of distance basis of their complementarity regarding interest, what they are seeking and what they are willing to offer, that distance will be calculated and basis of that some sort of a match will be proposed on every week basis.
Now, this is explicit communication that AI is at play. Now, let me take another example. You’re using credit card that has had a transaction at 2am in the morning. Suddenly you get a flurry of calls and messages asking for whether it is fraud, some sort of fraud alert has gone up. This does not not confirmed to your normal behaviour, hence, a fraud alert has gone up. Here, the customer does not know that. Customer thinks “Oh, you know what, My bank is very vigilant”. And because the transaction happened at a very odd time, they had the courtesy to call me and just alert that this transaction is happening? Are you the one who’s doing that? And here the bank has made no explicit communication about AI. But a more aware user will be able to see that this. For a layperson, this is not be possible.
Let me take a third example. Let’s look at the podcasting and the video editing software, spend ‘Descript’. Now in this script, what will happen is that if you want to edit out certain words, you can delete them. When you record your things, it will get converted to text. Now if you were to delete, edit something you basically delete those words and that part gets edited from the video. This is just a simple deletion. So there is no great logic that is required.
But then you type out certain words over there that this is what you want to say instead of this, you made a grammatical error, and you type it out. Now, that software will complete the sentence with the new words, and it will match your voice. So it will never happen that you will say that the part of the sentence is very disjointed, or the voice is very separate, they will match your tone, pitch, everything is matched so that it sounds as natural as possible to the model.
Now, here, there is the AI at play, but a lot of even aware audience will not be able to make it out. So that’s exactly what we’re saying that the user must not know AI is at play. The moment you have said that, you know, this is AI driven, then I’m not saying is spoiling the party. But it’s just that that’s that’s making AI as a epicentre, rather than the functionality, I think the hero is the value delivered to the customer rather than AI is a play. Check the OverDub Feature
Step #03 - Start with rule based systems.
Third, always start with the rule based on automation based feature. I think we already spoke about this at length. So you want to automate things, you want to build a simple, you want to drive down the costs, you want to cut down the staff from 1500 to 900. Okay, what are the most common queries? Can you put together? FAQ, simple thing? Can you put together an interactive or rule based chatbot? Where you put a series of question the person clicks on it? And then they answer it? Can you have a chat bot where those questions are pre-answered, and you’re just offering them the links to the FAQ’s. So start with basic rule based stuff, do nothing that is machine learning based without even understanding where you’re heading from a business perspective. Then move to statistical techniques. Because at every point in time, you will need to check – Are you offering the business value?
What I see in my limited experience is that many people want to implement jazzy stuff. ML driven chatbot to Bootstrap. Pump in custom corpus. Annotate data. Progressively build more domain specific corpuses. And this is the training data set. And why don’t you train and let’s get started. Now, there really isn’t enough experience in that particular corpus to train the datasets sufficiently to be effective in a production grade environment. And that’s when you see chatbots spewing out gibberish.
So it is not about introducing things for the sake of introducing it is about wanting to move step-by-step. If you’re a mission focused company whose only purpose in life is building chatbots for other businesses – Great! See if you’re Haptik, Haptik is a company that is based out of India, which is now Reliance Jio entity. So they have gone through the cycle. And their corpuses are significantly mature. They have very rich corpuses. Their models have undergone lots of learning over a period. It is an evolved company. So for them, some of this principle don’t apply. But for companies that are starting out, essentially product companies that are delivering value to the customer where AI is not their bread and butter, their bread and butter is delighting the customers. So for them, this is the roadmap item.
Step #04 - Mature Data Infrastructure
Once we do these things, we need to move and then start maturing the data infrastructure. What we mean by data infrastructure is and the only ways you can be very quick and dirty. You can have your JSON payloads coming in coming out, absolutely exchanging shaking hands all of those things. Then, as things move on, as your feature library keeps on growing, you will need to bring in more maturity over here. You will need to bring in more sustained sustainable scalable data infrastructure. With data infrastructure in place, you will end up doing a lot of feature engineering. What are typically called in simple English as derived metrics. But yes, there is some data that is getting reported. There are some derived metrics that are getting reported on top of it. I’m offering a very crude way of putting things with a very crude definition. But yes this is the thought process.
Step #05 - Start with an Offline Model
The next thing that we need to do is then we need to start putting together a machine learning model. The machine learning model can be ‘offline’, where you refresh the data manually, you build out the model you tested in the production or some sort of integration, testing, and then you put back in production as a deployment. And there are very well documented procedures to do that. The next innovation in that can be a ‘near-line’ kind of a model. And then there can be a completely ‘online’ kind of model. So there are again, ways this goes into the realm of DevOps, rather than just staying as a pure machine learning. But the decision to do all of these things, the data scientist, and the product manager both need to be involved, because garbage in garbage out is one hazards.
So if your data collection mechanism is robust, go ahead. If you suddenly start seeing people have heights of 27 feet and 28 feet consistently in your field to capture the heights of the people, then there is some sort of problem. But if your system has enough validation, built into your data, infrastructure is strong, missing values are appropriately reported, imputations are strong, then you need to build your machine learning model. You need to mature it, both things happen hand in hand.
The process typically starts with a historical data review. And within the historical data review, you typically come to understand what is it that the current state of data is? Where is it we need to arrive at and what validations we need to put in place? So typically, for a lot of medical data, you will have very strict norms regarding reporting some of these things. So like, you cannot have the blood pressure reported in negative. Well, that’s like a data entry error. But if you’re dealing with payloads, JSON, and other XML, CSV type files, all of these things can happen. So is your data infrastructure are robust enough to take care of it? Once all of these things are live, you need to have insight from the actual user always open.
So whenever you dole out a recommendation, you always taken feedback from the user. That was it. A good recommendation? Is this what you’re looking out for. And once you consistently ask this question to the user, the user gives you the input. And that can help you mature your model faster. With respect to a lot of classification based models, a lot of these things do help.
Great. I hope this is a set down some sort of framework for building out a first product features in the product that you’re envisioning to build for yourself.
Photo by Lucas Fonseca from Pexels

Join to get sneak peek into what's happening
I write about books, experiences, product, UX, EdTech, early stage growth, validation – mostly tech. Subscribe if these topics interest you. Once every 15 days emailer. I promise – No spam. (I am known for it otherwise) 😉



